

ÉTUDE DE CAS : CYCLISTIC BIKE SHARE
Scénario
Cyclistic Bike Share est une entreprise qui propose un programme de partage de vélo à Chicago depuis 2016. Leur but est de proposer une alternative de transport pratique, inclusive et écologique aux habitants de la ville de Chicago et à ses visiteurs. Dans notre cas, nous sommes en 2025, Cyclistic a bien évolué depuis ses débuts et comme toute entreprise, elle cherche à maximiser ses profits. Chez Cyclistic, il y a possibilité d’opter pour un abonnement annuel, de prendre un pass pour la journée ou de payer son trajet de façon unitaire. Les utilisateurs qui ont un abonnement annuel sont considérés comme des“membres”alors que les utilisateurs ponctuels (à la journée ou au trajet) sont considérés comme des utilisateurs “casual”. La direction de chez Cyclistic pense que les utilisateurs “membres” sont plus rentables que les “casual” pour la compagnie et aimerait en augmenter le nombre . Nous allons ici essayer de repérer les tendances qui existent dans les comportement des “Membres” et des “Casual” vis à vis de l’utilisation du programme de partage de vélo Cyclistic et faire des recommandation basées sur les données pour l'aider a augmenter le nombre de ses “membres”.
“Ask” Demander :
Nous analysons les besoins de Cyclistic avec les différentes parties prenantes du projet : L'équipe exécutive et Lily Moreno, La directrice du département Marketing dont je dépend dans le cadre de cette étude. Nous définissons ensemble le problème :
- En quoi les comportements des membres et des “casual” différent-ils en ce qui concerne l’utilisation de Cyclistic ?
- Pourquoi les utilisateurs occasionnels achèteraient-ils un abonnement annuel Cyclistic ?
- Comment Cyclistic peut utiliser les médias numériques pour inciter les utilisateurs occasionnels à devenir membres ?
Dans le cadre de ce cas d'études, Mme Moreno la directrice marketing de Cyclistic nous a assigné la première tâche [a)], celle de comparer les comportements des membres et des casual.
Préparer les données :
Nous aurons accès aux données historiques de Cyclistic pour l'année 2024, ces données sont des données privées de l’entreprise. Les données pour 2024 sont divisées en 12 fichiers mensuels organisés selon les colonnes suivante:
Les 12 fichiers combinées contiennent plus de 6 millions d’observations, nous utiliserons donc RStudio pour les traiter afin d'éviter les délais de traitement trop longs. Nous utiliserons aussi des API pour intégrer des données supplémentaires dans RStudio à partir d’autres applications (données géographiques et météorologiques), les Rpackages utilisés seront spécifiés au fur et à mesure.
Il est important de noter qu'en raison de problèmes de confidentialité des données , nous ne pouvons pas utiliser les informations personnelles identifiables des cyclistes. Cela signifie que nous ne pourrons pas relier les achats de pass aux numéros de carte de crédit pour déterminer si les utilisateurs occasionnels vivent dans la zone de service de Cyclistic ou s'ils ont acheté plusieurs pass individuels
De plus, nous pouvons garantir l'intégrité et la fiabilité des données en utilisant le test ROCCC :
- Les données sont fiables : elles sont représentatives de la population.
- Les données sont originales : la source primaire peut être identifiée.
- Les données sont complètes elles contiennent les informations essentielles nécessaires pour résoudre la tâche en cours.
- Les données sont actuelles : nous utilisons les données pour l'année 2024 en janvier 2025.
- Les données sont citées : elles proviennent d'une source vérifiée et crédible.
Nettoyer et organiser les données en vue de l’analyse:
Premièrement, J’ai téléchargé les 12 fichiers mensuels correspondant aux données de l'année 2024 a partir du dossier source suivant :
SOURCE DATAJe les ai téléchargés en format .csv et les ai stockées dans le fichier “CASE_STUDY” de mon “Desktop”. Vous pourrez trouver ci joint un journal des modifications de nettoyage apportées aux données en vue de l’analyse :
FICHIER NETTOYAGE DATAComme mentionné précédemment, nous utiliserons RStudio pour nettoyer les données. vous pouvez suivre le code “R” de mon analyse en suivant ce fichier Rscript :
RSCRIPTPour commencer, nous devons importer les 12 fichiers mensuels et les réunir en une seule table annuelle.
# Définir le chemin d'accès au dossier contenant les fichiers CSV
library("tidyverse")
folder_path <- "/Users/msayn47painter/Desktop/CASE_STUDY"
# Lister tous les fichiers CSV dans le dossier
file_list <- list.files(path = folder_path, pattern = "\\.csv$", full.names = TRUE)
# Charger tous les fichiers CSV dans une liste de dataframes
csv_data_list <- lapply(file_list, read_csv)
# Combiner tous les fichiers CSV en une seule table
bike_data <- bind_rows(csv_data_list)
Suppression des doublons :
# Suppression des doublons
bike_data <- bike_data %>% distinct()
# Verification de la suppression des doublons (doit etre =0)
nrow(bike_data) - nrow(distinct(bike_data))
Validation des formats :
# Verification des formats de date
bike_data <- bike_data %>%
mutate(
started_at = as.POSIXct(started_at, format = "%Y-%m-%d %H:%M:%S"),
ended_at = as.POSIXct(ended_at, format = "%Y-%m-%d %H:%M:%S")
)
# Verification des autres formats
bike_data <- bike_data %>%
mutate(
ride_id = as.character(ride_id),
rideable_type = as.character(rideable_type),
start_station_name = as.character(start_station_name),
start_station_id = as.character(start_station_id),
end_station_name = as.character(end_station_name),
end_station_id = as.character(end_station_id),
member_casual = as.character(member_casual)
)
Création de nouvelles colonnes :
# Creation d'une colonne pour mesurer la duree de chaque trajet
bike_data <- bike_data %>%
mutate(
trip_duration_secs = as.numeric(difftime(ended_at, started_at, units = "secs")),
trip_duration_min = trip_duration_secs / 60
)
# Creation d'une colonne pour le jour de la semaine ou le trajet a ete effectue
bike_data <- bike_data %>%
mutate(day_of_week = weekdays(started_at))
# Creation d'une colonne pour le mois
bike_data <- bike_data %>%
mutate(month = format(started_at, "%Y-%m"))
# Creation d'une colonne pour l'heure
bike_data <- bike_data %>%
mutate(hour = format(started_at, "%H"))
)
Nous ajouterons d’autres colonnes dans notre table bike_data par la suite.
Nous allons maintenant créer de nouvelles tables afin d’analyser quelles sont les préférences des différents types d’utilisateur en termes de temps de trajet :
# Creation de tables pour les differents temps de trajets par intervalles
# Moins de 1 seconde
less_than_1s <- bike_data %>% filter(trip_duration_secs < 1)
# Moins de 1 minute (60 secondes)
less_than_1min <- bike_data %>% filter(trip_duration_secs < 60)
# Moins de 4 minutes (240 secondes)
less_than_4min <- bike_data %>% filter(trip_duration_secs < 240)
# Moins de 15 minutes (900 secondes)
less_than_15min <- bike_data %>% filter(trip_duration_secs < 900)
# Moins de 1 heure (3600 secondes)
less_than_1hour <- bike_data %>% filter(trip_duration_secs < 3600)
# Entre 1 et 2 heures (3600 à 7200 secondes)
between_1and2hour <- bike_data %>% filter(trip_duration_secs >= 3600 & trip_duration_secs < 7200)
# Entre 2 et 6 heures (7200 à 21600 secondes)
between_2and6hour <- bike_data %>% filter(trip_duration_secs >= 7200 & trip_duration_secs < 21600)
# Entre 6 et 10 heures (21600 à 36000 secondes)
between_6and10hour <- bike_data %>% filter(trip_duration_secs >= 21600 & trip_duration_secs < 36000)
# Plus de 10 heures (36000 secondes et plus)
more_than_10hour <- bike_data %>% filter(trip_duration_secs >= 36000)
En analysant ces tables je me suis rendu compte que la table moins de 1 seconde avait des durées de temps de trajet négatifs. Plutôt que de supprimer ces données aberrantes j’ai émis l'hypothèse que les “started_at” et “ended_at” avaient pu être inversées. J’ai donc supprimé les tables et effectué une commande permettant d’inverser les dates “started at” et “ended at” pour les trajets ayant une “tripduration_secs” négative. Nous réeffectuons la commande pour la création de tables par intervalles de temps par la suite.
# Certains temps de trajet sont a l'envers :
# Hypothese : les dates de depart et d'arrivee sont inversees.
# Remise a l'endroit des dates inversees
bike_data <- bike_data %>% mutate(started_at = if_else(trip_duration_secs < 0, ended_at, started_at),
ended_at = if_else(trip_duration_secs < 0, started_at, ended_at),
trip_duration_secs = as.numeric(difftime(ended_at, started_at, units = "secs")),
trip_duration_min = trip_duration_secs / 60)
En analysant les différentes tables je me suis rendu compte qu’il y avait encore des lignes avec des données manquantes, j’ai donc décidé de faire un dernier “round” de nettoyage general :
# supprimer les valeurs manquantes
bike_data <- bike_data %>% drop_na()
clean_tables <- function(...) {
tables <- list(...)
cleaned_tables <- lapply(tables, drop_na)
return(cleaned_tables)
}
# Utilisation de la fonction
list_cleaned <- clean_tables(less_than_1s, less_than_1min, less_than_4min,
less_than_15min, less_than_1hour,
between_1and2hour, between_2and6hour,
between_6and10hour, more_than_10hour)
# Attribution des résultats aux tables originales
less_than_1s <- list_cleaned[[1]]
less_than_1min <- list_cleaned[[2]]
less_than_4min <- list_cleaned[[3]]
less_than_15min <- list_cleaned[[4]]
less_than_1hour <- list_cleaned[[5]]
between_1and2hour <- list_cleaned[[6]]
between_2and6hour <- list_cleaned[[7]]
between_6and10hour <- list_cleaned[[8]]
more_than_10hour <- list_cleaned[[9]]Analyse des données.
Nous arrivons maintenant à la partie la plus excitante de cette étude de cas : L’analyse.
ANALYSE GENERALE
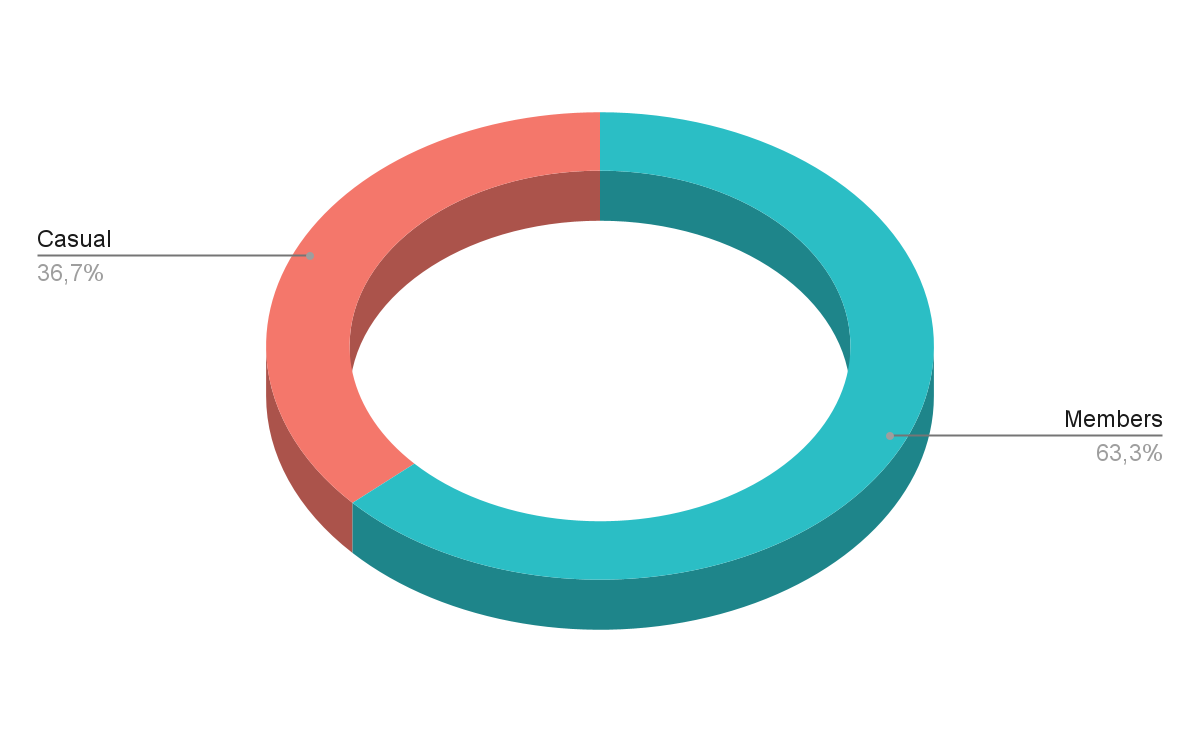
Nous allons commencer par analyser les variables individuellement avant de les mettre en relation. Premièrement, quel est le pourcentage de membres par rapport au total d’utilisateurs en 2024 ?
member_casual count percentage
| Nombre | Pourcentage | |
| Casual | 2 151 658 | 36.7% |
| Member | 3 708 910 | 63.3% |
En 2024 il y a eu 63.3% des utilisateurs ayant effectué des trajets avec Cyclistic étaient des membres et 36.7 étaient des casuals
# DEBUT DE L"ANALYSE DES DONNEES
# Analyse individuelle des differentes variables.
# Pourcentages de "membres" et "casual"
library(dplyr)
percentage_member_casual <- function(data) {
# Filtrer les données pour l'année 2024
data_2024 <- data %>% filter(format(started_at, "%Y") == "2024")
# Calculer le nombre total de trajets
total_rides <- nrow(data_2024)
# Calculer le nombre de trajets par type d'utilisateur
counts <- data_2024 %>%
group_by(member_casual) %>%
summarise(count = n(), .groups = "drop")
# Ajouter la colonne de pourcentage
counts <- counts %>%
mutate(percentage = (count / total_rides) * 100)
return(counts)
}
# Utilisation de la fonction
percentage_results <- percentage_member_casual(bike_data)
# Affichage des résultats
print(percentage_results)
Quel est le mois où les utilisateurs ont eu le plus recours au service de Bike Share ?
| Septembre 2024 | 820867 | 14.0 % |
Le mois de Septembre 2024 a été le plus fréquenté avec un total de 820 867 trajets ce qui represente 14% des trajets totaux en 2024.
Quel est le mois où les utilisateurs ont eu le moins recours au service de Bike Share ?
| Jannvier 2024 | 144873 | 2.47 % |
Le mois de Janvier 2024 a été le mois le moins fréquenté par les utilisateurs de Cyclistic en 2024 avec 144 873 trajets ce qui représente 2.47% du total des trajets.
# Mois le plus frequente et le moins frequente de l'annee 2024 :
# Mois le plus frequente ;
most_frequent_month_percentage <- function(data) {
# Filtrer les données pour l'année 2024
data_2024 <- data %>% filter(format(started_at, "%Y") == "2024")
# Extraire le mois et compter les trajets
monthly_counts <- data_2024 %>%
mutate(month = format(started_at, "%Y-%m")) %>%
group_by(month) %>%
summarise(total_rides = n(), .groups = "drop")
# Calcul du total des trajets sur l'année
total_rides_2024 <- sum(monthly_counts$total_rides)
# Trouver le mois avec le maximum de trajets
most_frequent <- monthly_counts %>%
filter(total_rides == max(total_rides)) %>%
mutate(percentage = (total_rides / total_rides_2024) * 100)
return(most_frequent)
}
# Mois le moisn frequente :
least_frequent_month_percentage <- function(data) {
# Filtrer les données pour l'année 2024
data_2024 <- data %>% filter(format(started_at, "%Y") == "2024")
# Extraire le mois et compter les trajets
monthly_counts <- data_2024 %>%
mutate(month = format(started_at, "%Y-%m")) %>%
group_by(month) %>%
summarise(total_rides = n(), .groups = "drop")
# Calcul du total des trajets sur l'année
total_rides_2024 <- sum(monthly_counts$total_rides)
# Trouver le mois avec le minimum de trajets
least_frequent <- monthly_counts %>%
filter(total_rides == min(total_rides)) %>%
mutate(percentage = (total_rides / total_rides_2024) * 100)
return(least_frequent)
}
# Utilisation de la fonction
least_frequent_month_percentage(bike_data)
ANALYSE DE L'ÉVOLUTION ANNUELLE PAR TYPE D’UTILISATEUR
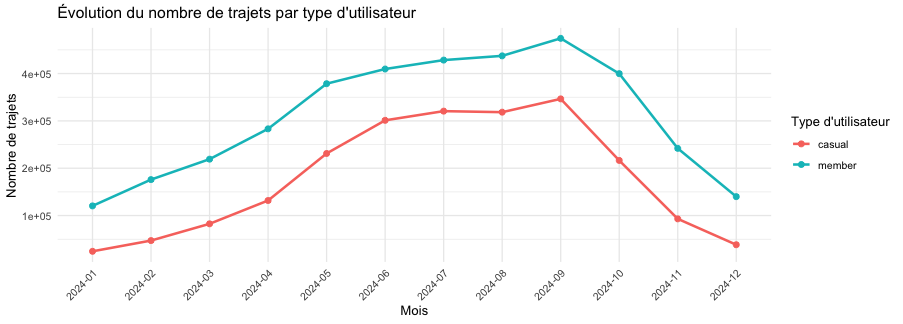
Intéressons nous maintenant à l'évolution de la tendance continue sur l'année 2024
# Creation d'un graphique evolution du nombre d'utilisateurs par rapport au temps
library("ggplot2")
library("dplyr")
monthly_counts <- bike_data %>%
group_by(month, member_casual) %>%
summarise(count = n(), .groups = "drop")
ggplot(monthly_counts, aes(x = month, y = count, color = member_casual, group = member_casual)) +
geom_line(size = 1) +
geom_point(size = 2) +
labs(title = "Évolution du nombre de trajets par type d'utilisateur",
x = "Mois",
y = "Nombre de trajets",
color = "Type d'utilisateur") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
Sans surprise, les utilisateurs ont beaucoup plus utilisé le service de Bikeshare pendant les mois d'été, il y a une grosse augmentation du nombre d’utilisateurs au cours du mois d’avril probablement expliquée par le retour des beaux jours. Le pic de l'activité pour l'année 2024 a été en Septembre.
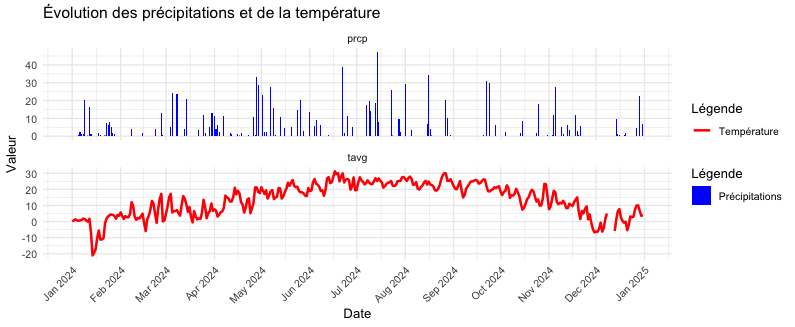
ANALYSE DES CONDITIONS MÉTÉOROLOGIQUES
Nous allons maintenant intégrer des données de température et de précipitations pour Chicago en 2024 grâce à un jeu de données trouvé sur Weatherstack. Le fichier csv “export.csv” contient les données météorologiques pour chaque journée de l'année 2024, il est organisé selon les colonnes suivantes :
Pour alléger le processus d’analyse, nous n'utilisons que les variables “tavg” et “prcp”
De plus, nous pouvons garantir l'intégrité et la fiabilité des données en utilisant le test ROCCC :
- Les données sont fiables : elles sont représentatives de la population.
- Les données sont originales : la source primaire peut être identifiée.
- Les données sont complètes elles contiennent les informations essentielles nécessaires pour résoudre la tâche en cours.
- Les données sont actuelles : nous utilisons les données pour l'année 2024 en janvier 2025.
- Les données sont citées : elles proviennent d'une source vérifiée et crédible.
# Ajout des variables de precipitations et de temperature
library(dplyr)
library(lubridate)
# Charger le fichier export.csv
weather_data <- read.csv("/Users/msayn47painter/Desktop/export.csv")
# Convertir la colonne "date" en type Date
weather_data$date <- as.Date(weather_data$date)
# Charger bike_data (si ce n'est pas déjà fait)
# bike_data <- read.csv("chemin/vers/bike_data.csv")
# Extraire les dates de la colonne 'started_at' de bike_data et les convertir en type Date
bike_data$started_at <- as.POSIXct(bike_data$started_at)
# Extraire uniquement la date (sans l'heure) de started_at
bike_data$date <- as.Date(bike_data$started_at)
# Joindre les données météorologiques avec bike_data sur la date
bike_data <- left_join(bike_data, weather_data[, c("date", "tavg", "prcp")], by = "date")
# Renommer les colonnes pour correspondre aux nouvelles colonnes attendues
bike_data <- bike_data %>%
rename(temperature = tavg, precipitation = prcp)
# Vérifier les premières lignes pour s'assurer que tout est bien intégré
head(bike_data)
# Analyse des tempertures et precipitations annuelles.
# Charger les bibliothèques nécessaires
library(ggplot2)
library(dplyr)
library(lubridate)
library(tidyr)
# avec les colonnes "date" (format YYYY-MM-DD), "tavg" (température moyenne) et "prcp" (précipitations)
# Convertir la colonne date en format Date et extraire le mois pour s'assurer que tous les mois apparaissent
weather_data$date <- as.Date(weather_data$date)
weather_data$month <- format(weather_data$date, "%Y-%m") # Format YYYY-MM pour affichage mensuel
# Transformer les données au format long pour ggplot
weather_long <- weather_data %>%
select(date, month, tavg, prcp) %>%
pivot_longer(cols = c(tavg, prcp), names_to = "variable", values_to = "value")
# Créer le graphique avec les précipitations en barres et la température en ligne
ggplot(weather_long, aes(x = date, y = value, group = variable)) +
geom_col(data = subset(weather_long, variable == "prcp"), aes(fill = "Précipitations"), width = 0.7) +
geom_line(data = subset(weather_long, variable == "tavg"), aes(color = "Température"), size = 1) +
scale_x_date(date_breaks = "1 month", date_labels = "%b %Y") + # Affichage de tous les mois
scale_fill_manual(values = c("Précipitations" = "blue")) +
scale_color_manual(values = c("Température" = "red")) +
facet_wrap(~variable, scales = "free_y", ncol = 1) + # Une colonne, chaque variable sur un graphique séparé
labs(title = "Évolution des précipitations et de la température",
x = "Date",
y = "Valeur",
fill = "Légende",
color = "Légende") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) # Incline les labels des mois pour meilleure lisibilité
Nous allons maintenant pousser plus loin notre étude pour déterminer l’effet de la température et des précipitations sur chacun des différents types d’utilisateurs et essayer de quantifier cet effet. Pour cela nous utiliserons une régression linéaire dans RStudio.
RÉGRESSION LINÉAIRE
Le nombre de trajets expliqués par la température et les précipitations pour chaque type de client indépendamment.
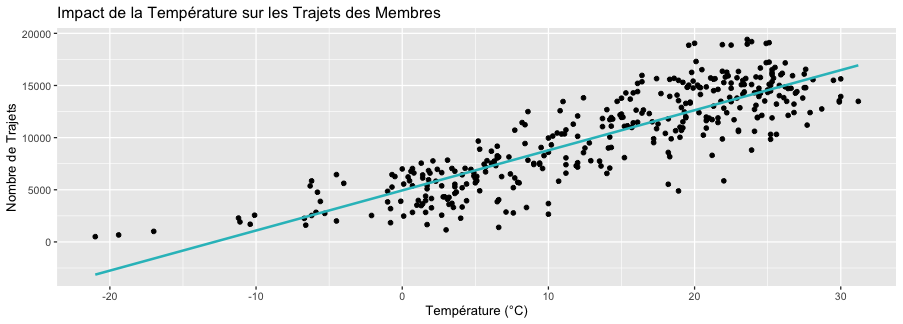
Le but ici est de mesurer la sensibilité à la température et aux précipitations pour chaque type de client. L’influence de la température sur le recours au service de location de vélo est il plus important chez les membres ou chez les casual ? Quelle est cette influence en termes de mesure ?
Modèle :
n_trips = β0 + β1×temperature + β2×precipitation + ϵ
La régression linéaire sera performée sur 2 ensembles distinct :
- Les données pour les membres
- Les données pour les casual
# Creation d'une regression lineaire pour mesurer la sensibilite de chaque type de consommateur
# Par rapport a la temperature et aux precipitations sur le nombre de trajets
# Séparer les données en fonction du type de consommateur (membres vs casuals)
member_data <- daily_data %>% filter(member_casual == "member")
casual_data <- daily_data %>% filter(member_casual == "casual")
# Régression pour les membres
member_model <- lm(n_trips ~ temperature + precipitation, data = member_data)
summary(member_model)
# Régression pour les casuals
casual_model <- lm(n_trips ~ temperature + precipitation, data = casual_data)
summary(casual_model)
RÉSULTATS:
Résultats membres:
Call:
lm(formula = n_trips ~ temperature + precipitation, data = casual_data)
Residuals:
Min 1Q Median 3Q Max
-5349.4 -1573.5 -416.8 1097.3 9635.7
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1235.08 231.90 5.326 1.78e-07 ***
temperature 371.51 13.66 27.199 < 2e-16 ***
precipitation -124.40 19.73 -6.306 8.42e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2615 on 359 degrees of freedom
(4 observations deleted due to missingness)
Multiple R-squared: 0.675, Adjusted R-squared: 0.6732
F-statistic: 372.9 on 2 and 359 DF, p-value: < 2.2e-16 Température : Le coefficient pour la température est 371.51, ce qui signifie qu'une augmentation de 1°C correspond à une augmentation de 371.51 trajets en moyenne pour les casuals. Cet effet positif sur l'utilisation des vélos est également significatif.
Précipitations : Le coefficient pour les précipitations est -124.40, ce qui montre que plus il pleut, moins les casuals utilisent leur vélo, avec une diminution moyenne de 124.40 trajets pour chaque unité d'augmentation des précipitations.
R² : Le R² est de 0.675, ce qui signifie que 67.5% de la variation du nombre de trajets des casuals peut être expliquée par la température et les précipitations.
Résultats casuals:
Call:
lm(formula = n_trips ~ temperature + precipitation, data = casual_data)
Residuals:
Min 1Q Median 3Q Max
-5349.4 -1573.5 -416.8 1097.3 9635.7
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1235.08 231.90 5.326 1.78e-07 ***
temperature 371.51 13.66 27.199 < 2e-16 ***
precipitation -124.40 19.73 -6.306 8.42e-10 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2615 on 359 degrees of freedom
(4 observations deleted due to missingness)
Multiple R-squared: 0.675, Adjusted R-squared: 0.6732
F-statistic: 372.9 on 2 and 359 DF, p-value: < 2.2e-16Température : Le coefficient pour la température est 371.51, ce qui signifie qu'une augmentation de 1°C correspond à une augmentation de 371.51 trajets en moyenne pour les casuals. Cet effet positif sur l'utilisation des vélos est également significatif. Précipitations : Le coefficient pour les précipitations est -124.40, ce qui montre que plus il pleut, moins les casuals utilisent leur vélo, avec une diminution moyenne de 124.40 trajets pour chaque unité d'augmentation des précipitations. R² : Le R² est de 0.675, ce qui signifie que 67.5% de la variation du nombre de trajets des casuals peut être expliquée par la température et les précipitations.
# Creations de visualisation pour la relation entre temperature et le nombre de trajets.
# Visualisation pour les membres
ggplot(member_data, aes(x = temperature, y = n_trips)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE, color = "#2bbec5") + # Bleu turquoise pour les membres
labs(title = "Impact de la Température sur les Trajets des Membres",
x = "Température (°C)", y = "Nombre de Trajets")
# Visualisation pour les casuals
ggplot(casual_data, aes(x = temperature, y = n_trips)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE, color = "#f4776b") + # Rouge saumon pour les casuals
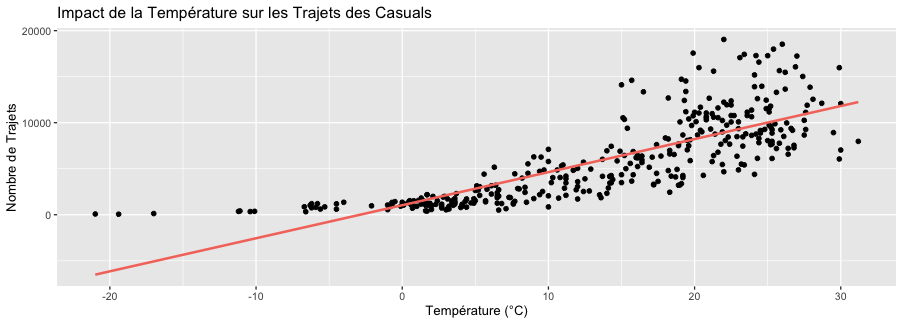
labs(title = "Impact de la Température sur les Trajets des Casuals",
x = "Température (°C)", y = "Nombre de Trajets")
# Creations de visualisation pour l relation entre les precipitations et le nombre de trajets.
# Visualisation pour les membres
ggplot(member_data, aes(x = precipitation, y = n_trips)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE, color = "#2bbec5") + # Bleu turquoise pour les membres
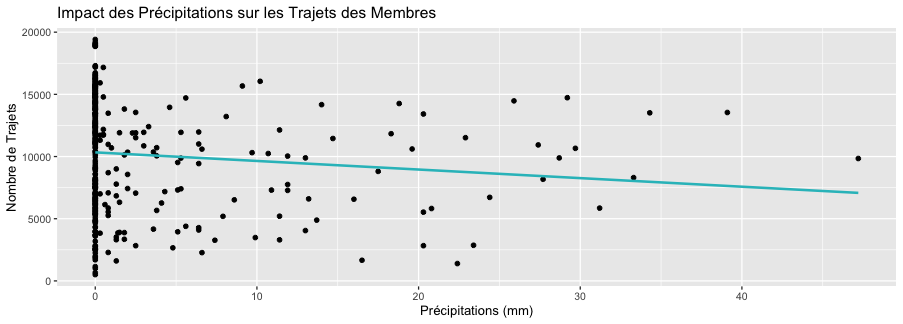
labs(title = "Impact des Précipitations sur les Trajets des Membres",
x = "Précipitations (mm)", y = "Nombre de Trajets")
# Visualisation pour les casuals
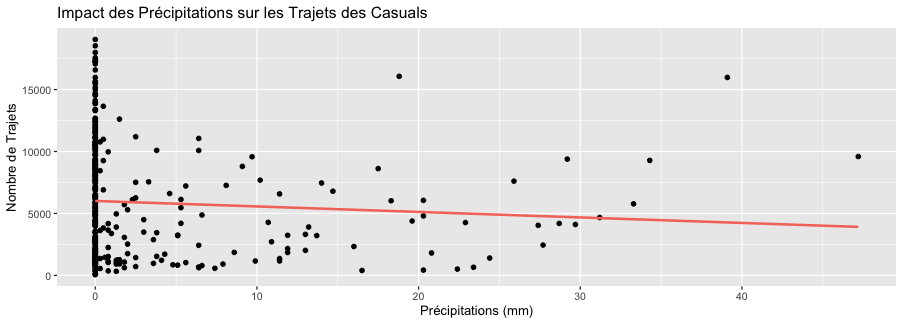
ggplot(casual_data, aes(x = precipitation, y = n_trips)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE, color = "#f4776b") + # Rouge saumon pour les casuals
x = "Précipitations (mm)", y = "Nombre de Trajets")
ANALYSE DES HABITUDES D'UTILISATION HEBDOMADAIRES ET QUOTIDIENNES PAR TYPE D’UTILISATEUR.
Pour continuer notre analyse, nous allons maintenant nous intéresser aux préférences des utilisateurs et identifier des tendances dans les habitudes de chaque type de consommateur. Pour cela, nous utiliserons des graphiques à barres pour illustrer l’utilisation journalière et hebdomadaire du programme de partage de vélos.
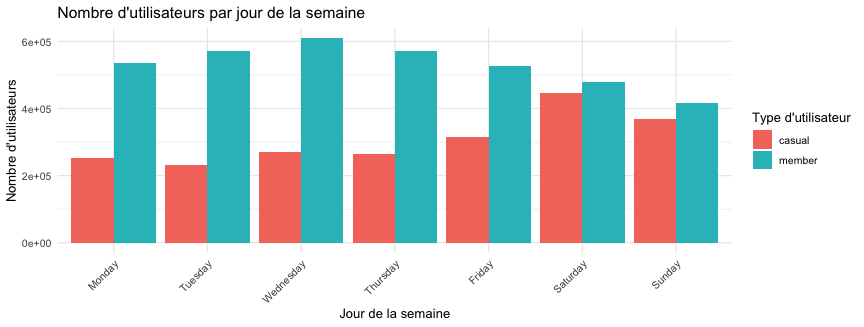
Jour de la semaine
# Creation d'un graphique pour definir le jour de la semaines ou les differents utilisateurs sont actifs.
library(ggplot2)
library(dplyr)
# Groupement des données par jour de la semaine et type d'utilisateur
bike_data_weekday <- bike_data %>%
group_by(day_of_week, member_casual) %>%
summarise(count = n()) %>%
ungroup()
# Création du graphique
ggplot(bike_data_weekday, aes(x = day_of_week, y = count, fill = member_casual)) +
geom_bar(stat = "identity", position = "dodge") +
scale_fill_manual(values = c("member" = "#2bbec5", "casual" = "#f4776b")) +
labs(title = "Nombre d'utilisateurs par jour de la semaine",
x = "Jour de la semaine",
y = "Nombre d'utilisateurs",
fill = "Type d'utilisateur") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
On voit ici que les membres ont une utilisation beaucoup plus constante du service de partage de vélos que les casuals avec une baisse de leur utilisation en fin de semaine. Les casuals, eux, ont une claire hausse de leur utilisation en fin de semaine.
Heures de la journée
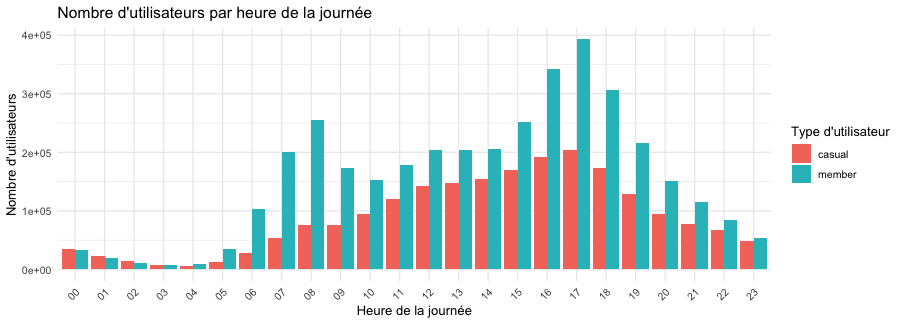
Ici on voit bien qu’il y a 2 pics d’utilisation pour les membres entre 06h00 et 09h00 et entre 16h et 18h ce qui peut correspondre à des horaires de bureaux. L'évolution de l’utilisation des casuals est elle plus constante au cours de la journée avec un pic d’utilisation à 17h.
ANALYSE DES PRÉFÉRENCES EN TERME DE TYPE DE VÉLO PAR TYPE D’UTILISATEUR.
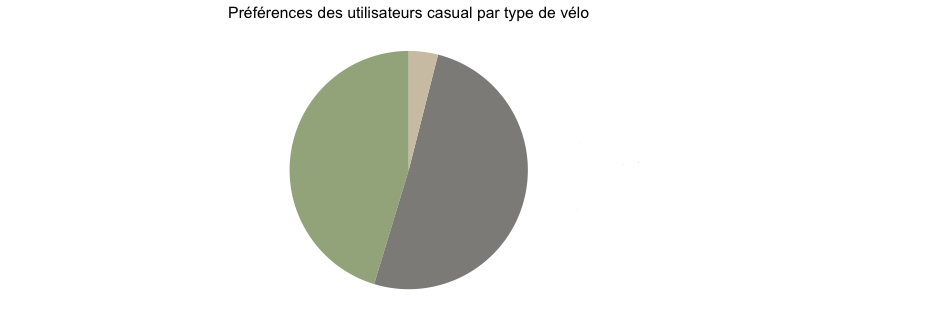
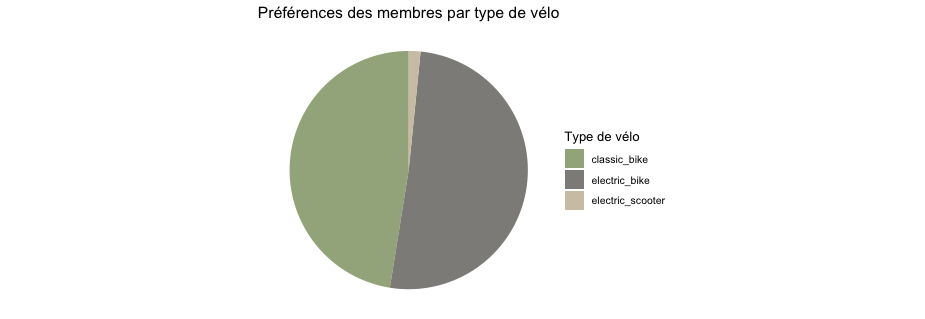
# Creation de graphiques par type d'utilisateur pour les velos
library(ggplot2)
library(dplyr)
# Préparation des données pour les membres et casuals
bike_data_members <- bike_data %>%
filter(member_casual == "member") %>%
count(rideable_type)
bike_data_casual <- bike_data %>%
filter(member_casual == "casual") %>%
count(rideable_type)
# Graphique en donut pour les membres
ggplot(bike_data_members, aes(x = "", y = n, fill = rideable_type)) +
geom_bar(stat = "identity", width = 1) +
coord_polar(theta = "y") +
scale_fill_manual(values = c("electric_bike" = "#8E8D8A", # Gris clair pour les vélos électriques
"classic_bike" = "#A3B18C", # Vert olive pour les vélos classiques
"docked_bike" = "#F1C6A4", # Beige pour les vélos dockés
"electric_scooter" = "#D1C6B1")) + # Gris pâle pour les scooters électriques
labs(title = "Préférences des membres par type de vélo", fill = "Type de vélo") +
theme_void() +
theme(legend.position = "right") +
theme(plot.title = element_text(hjust = 0.5))
# Graphique en donut pour les utilisateurs casual
ggplot(bike_data_casual, aes(x = "", y = n, fill = rideable_type)) +
geom_bar(stat = "identity", width = 1) +
coord_polar(theta = "y") +
scale_fill_manual(values = c("electric_bike" = "#8E8D8A", # Gris clair pour les vélos électriques
"classic_bike" = "#A3B18C", # Vert olive pour les vélos classiques
"docked_bike" = "#F1C6A4", # Beige pour les vélos dockés
"electric_scooter" = "#D1C6B1")) + # Gris pâle pour les scooters électriques
labs(title = "Préférences des utilisateurs casual par type de vélo", fill = "Type de vélo") +
theme_void() +
theme(legend.position = "right") +
theme(plot.title = element_text(hjust = 0.5))
Ici on peut voir que les casual ont un plus recours aux scooters électriques que les membres. Peut-être y a t il ici une information importante qui demanderait une analyse de marché plus approfondie, nous reviendrons la dessus dans la partie “recommandations”.
ANALYSE DES STATIONS
Nous allons maintenant nous intéresser aux préférences des utilisateurs concernant les types de stations. Pour cela nous ferons un graphique des 5 stations les plus utilisées et une carte interactive de Chicago pour situer les stations géographiquement. Afin d’importer des données géographiques sur chicago nous utiliserons une API google maps pour importer nos données et utiliserons le package ”leaflet” pour lire les données sur RStudio. Le code R pour la création de cette carte interactive est fastidieux et long. Pour suivre ce code veuillez vous référer au Script R.
Carte interactive
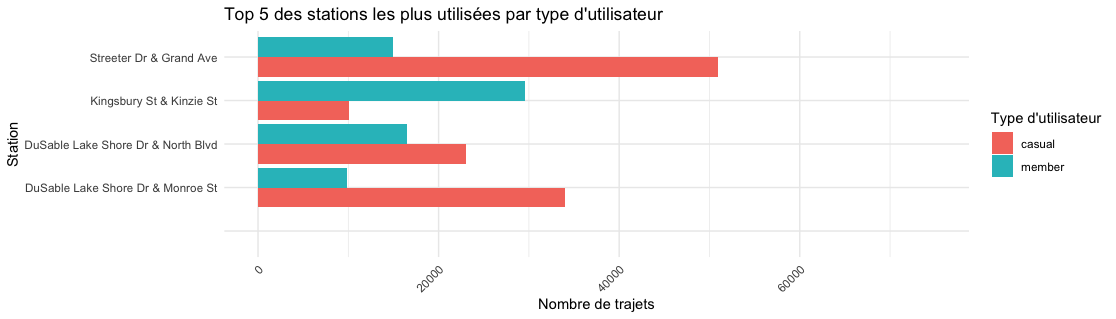
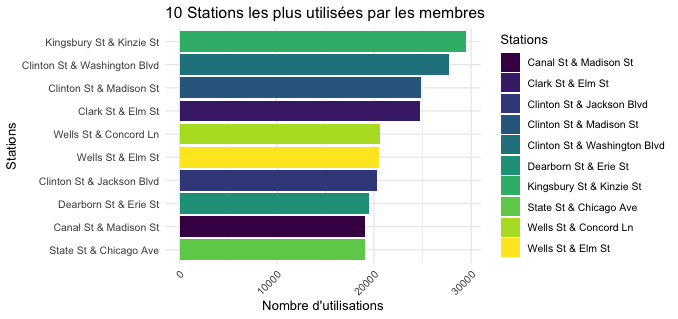
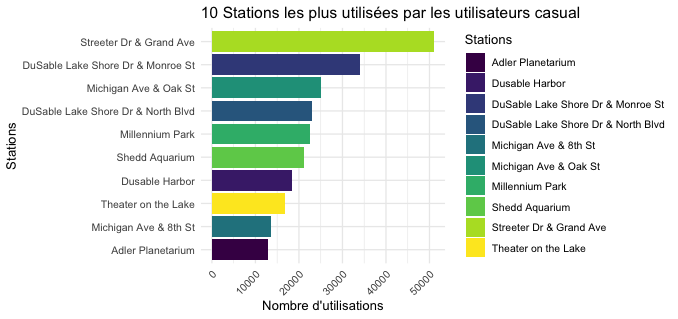
La carte et les graphiques offrent beaucoup d’informations importantes et pertinentes. Premièrement les causals ont une concentration plus forte de leur utilisation sur certaines stations, tandis que la répartition des stations utilisées par les membres est plus uniforme. Ce qui offre une opportunité de taille, nous reviendrons la dessus dans nos recommandations.
Nous pouvons aussi remarquer que les stations utilisées par les casuals sont globalement plus situées sur le bord du lac (est) alors que les membres utilisent des stations plus dans le centre ville (west).
ANALYSE DES DURÉES DE TRAJETS PAR TYPE D’UTILISATEUR
Pour finir, nous allons analyser et comparer les temps de trajets pour les utilisateurs par type d’utilisateurs. Pour cela nous allons utiliser les tables créées par intervalles de durée :
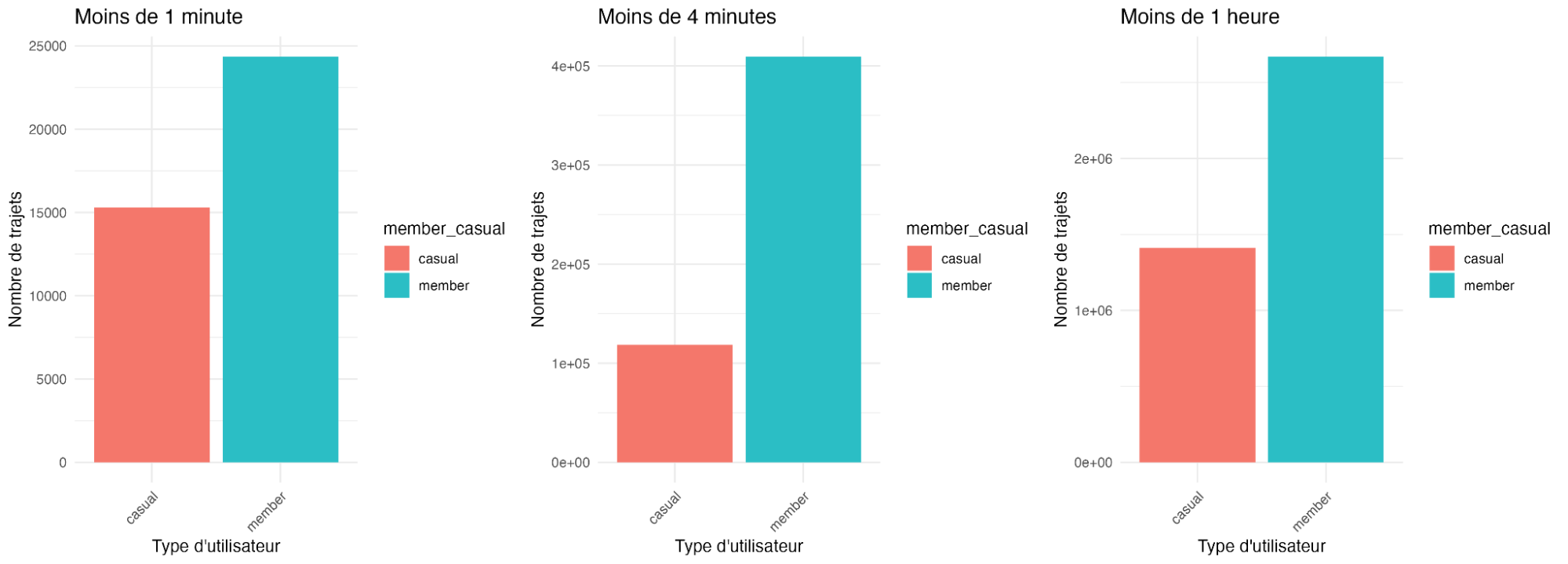
On voit bien ici que les utilisateurs casuals utilisent le service de partage de vélos pour des trajets en moyenne plus longs que les membres
# Creation d'un graphique representant l'utilisation par type de membres dans differents intervalles de temps
library(ggplot2)
library(dplyr)
# Création des intervalles de temps pour la durée des trajets
bike_data <- bike_data %>%
mutate(duration_category = case_when(
trip_duration < 1 ~ "less_than_1s",
trip_duration < 60 ~ "less_than_1min",
trip_duration < 240 ~ "less_than_4min",
trip_duration < 900 ~ "less_than_15min",
trip_duration < 3600 ~ "less_than_1hour",
trip_duration < 7200 ~ "between_1and2hour",
trip_duration < 21600 ~ "between_2and6hour",
trip_duration < 36000 ~ "between_6and10hour",
TRUE ~ "more_than_10hour"
))
# Compter le nombre de trajets par catégorie de durée et par type d'utilisateur
bike_data_duration <- bike_data %>%
count(duration_category, member_casual) %>%
arrange(factor(duration_category, levels = c("less_than_1s", "less_than_1min",
"less_than_4min", "less_than_15min",
"less_than_1hour", "between_1and2hour",
"between_2and6hour", "between_6and10hour",
"more_than_10hour")))
# Générer le graphique
ggplot(bike_data_duration, aes(x = duration_category, y = n, fill = member_casual)) +
geom_bar(stat = "identity", position = "dodge") +
scale_fill_manual(values = c("member" = "#2bbec5", "casual" = "#f4776b")) +
labs(title = "Répartition des trajets par durée et type d'utilisateur",
x = "Durée du trajet",
y = "Nombre de trajets",
fill = "Type d'utilisateur") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
Interprétations
PIC DE L'UTILISATION EN SEPTEMBRE :
Plusieurs facteurs peuvent expliquer ce pic : le retour à l'école des étudiants (il serait intéressant dans ce cas de cibler cette clientèle dans notre campagne marketing afin d'inciter les étudiants “casual” à devenir “membres”). Des pistes de ciblage de cette clientèle seront évoquées dans la partie “recommandations”. Les 29 et 30 Septembres 2024, a eu lieu un festival de musique “The World Music Festival Chicago” il y a beaucoup d'événements gratuits dans le cadre de ce festival répartis sur 11 sites différents dans tout Chicago. On pourrait imaginer que ce type de festival influence positivement l’utilisation de Cyclistic par les utilisateurs. Pour vérifier cette hypothèse, nous analyserons quels sont les 5 jours de Septembre ayant enregistré la plus grosse activité.
| Jour | Nombre de trajets |
| 2024-09-21 | 34698 |
| 2024-09-14 | 33705 |
| 2024-09-01 | 31869 |
| 2024-09-20 | 30814 |
| 2024-09-19 | 30671 |
Les journées ou les utilisateurs ont le plus utilisé le service de Cyclistic en Septembre 2024 sont les 21, 14, 01, 20 et 19 Septembre. Cela ne concorde pas avec les dates du festival “The World Music Festival Chicago”, toutefois, il y avait un autre festival “Oktoberfest” à Lincoln Park le 21/09/2024. Si la station de Lincoln Park enregistre un nombre inhabituel de trajets, il pourrait être pertinent d’envisager une action Marketing directement dans ce festival les prochaines années.
| Station | Nombre de trajets ( arrivées + départs ) |
| Streeter Dr & Grand Ave | 1267 |
| DuSable Lake Shore Dr & North Blvd | 980 |
| Michigan Ave & Oak St | 687 |
| DuSable Lake Shore Dr & Monroe St | 652 |
| Theater on the Lake | 574 |
| Clark St & Lincoln Ave | 535 |
| Wells St & Concord Ln | 523 |
| Millennium Park | 502 |
| Clark St & Armitage Ave | 467 |
La 2eme station la plus utilisée le 21 Septembre est une station proche du Park Lincoln : DuSable Lake Shore Dr & North Blvd, mais de façon générale, les stations les plus utilisées ce jour là sont les stations proches du Lac. Nous proposerons des recommandations plus détaillées dans la partie “recommandations”
# Analyse supplementaire pour les journees les plus actives de Septembre
## (Y-a-til une augmentation de l'activite pendant "World Music festival Chicago" les 29 & 30 Septembres)
top_5_active_days_september <- function(data) {
# Filtrer les données pour septembre 2024
data_september <- data %>%
filter(format(started_at, "%Y-%m") == "2024-09")
# Grouper par jour et compter les trajets
daily_counts <- data_september %>%
mutate(day = format(started_at, "%Y-%m-%d")) %>%
group_by(day) %>%
summarise(total_rides = n(), .groups = "drop")
# Trier et sélectionner les 5 jours les plus actifs
top_5_days <- daily_counts %>%
arrange(desc(total_rides)) %>%
head(5)
return(top_5_days)
}
# Utilisation de la fonction
top_5_active_days_september(bike_data)
# Analyse supplementaire : Stations les plus utilisees le jour le plus actif de Septembre 2024
library(dplyr)
library(tidyr) # Ajoute cette ligne pour utiliser replace_na()
top_stations_sept21 <- function(data) {
# Filtrer les données pour le 21 septembre 2024
data_sept21 <- data %>%
filter(format(started_at, "%Y-%m-%d") == "2024-09-21")
# Compter les départs par station
departures <- data_sept21 %>%
group_by(start_station_name) %>%
summarise(total_departures = n(), .groups = "drop")
# Compter les arrivées par station
arrivals <- data_sept21 %>%
group_by(end_station_name) %>%
summarise(total_arrivals = n(), .groups = "drop")
# Fusionner les deux tables sur le nom des stations
station_usage <- full_join(departures, arrivals,
by = c("start_station_name" = "end_station_name")) %>%
replace_na(list(total_departures = 0, total_arrivals = 0)) %>% # Corrige les NA
mutate(total_traffic = total_departures + total_arrivals) %>%
arrange(desc(total_traffic))
# Renommer la colonne des stations
station_usage <- station_usage %>%
rename(station_name = start_station_name)
return(station_usage)
}
# Utilisation de la fonction
top_stations_sept21(bike_data)
CONDITIONS MÉTÉOROLOGIQUES
Température : La température a un effet positif sur le nombre de trajets, à la fois pour les membres et les casuals, bien que l'effet soit légèrement plus marqué chez les membres (399.82 trajets par °C contre 371.51 trajets par °C pour les casuals). Cela montre que la température influence de manière significative la fréquentation des vélos pour les deux groupes. Plus il fait chaud, plus il y a de vélos.
Précipitations : Les précipitations ont un effet négatif sur le nombre de trajets, à la fois pour les membres et les casuals, mais l'effet est plus prononcé pour les casuals. Pour chaque unité d'augmentation des précipitations, le nombre de trajets diminue davantage chez les casuals (124.40 trajets) que chez les membres (154.47 trajets). Comparaison des groupes : Les membres semblent plus sensibles aux changements de température, avec un effet plus marqué que les casuals. Cependant, les casuals sont plus sensibles aux précipitations. Cela peut s’expliquer par le fait que les membres paient déjà pour leur abonnement, c’est comme s' ils avaient déjà payé pour leur jour de pluie, les casuals, eux, peuvent opter pour un moyen de transport différent les jours de pluie sans avoir à assumer le coût d'opportunité lié au fait de payer un abonnement. Pour les 2 groupes, on remarque que les observations sont plus dispersées autour de la ligne de regression pour les précipitations, ce qui signifie que l'impact des précipitations est moins important que celui de la température.
Comparaison des groupes : Les membres semblent plus sensibles aux changements de température, avec un effet plus marqué que les casuals. Cependant, les casuals sont plus sensibles aux précipitations.
Dans l’analyse des données météorologiques, on remarque aussi que les mois de Juillet Août ont été plus pluvieux que le mois de Septembre ce qui peut venir donner une explication supplémentaire pour le pic d’utilisation annuel en Septembre.
HABITUDES QUOTIDIENNES ET HEBDOMADAIRES
Les membres ont une utilisation du service de partage de vélos répartie sur toute la semaine avec une petite baisse le week end tandis que les casual utilisent massivement les vélos les samedi dimanche et moins le reste de la semaine. Les pics d’utilisation journaliers pour les membres sont entre 06h et 09h et entre 16 et 18h, l'évolution de l’utilisation des vélos par les casuals est elle plus constante au cours de la journée. On peut en déduire que les membres utilisent plus le service de partage de vélos pour se rendre au travail tandis que les casuals semblent plus avoir une utilisation de type “loisir”.
TYPES DE VÉLOS UTILISÉS
Les deux types d’utilisateurs préfèrent les vélos électriques. Toutefois les casuals utilisent plus les scooters électriques que les membres.
STATIONS LES PLUS UTILISÉES
Les casuals ont une nette concentration de leur utilisation du service sur certaines stations tandis que les membres ont une utilisation des stations plus uniformément répartie. Si les membres utilisent leur vélo majoritairement pour aller au travail cela peut expliquer cette meilleure répartition (car les membres ne travaillent pas tous au même endroit). En s'intéressant à la carte géographique, on se rend compte que les stations les plus utilisées par les casuals sont des stations situées au bord de l’eau, et les membres des stations situées plus en ville ou dans des zones résidentielles, les 2 stations proches de la gare sont aussi des stations de choix pour les membres. Les casuals aiment particulièrement les stations du port ou de Lincoln Park ainsi que toutes les stations proches du lac de manière générale. Encore un indice nous permettant d'affirmer que les membres utilisent en générale le service pour le travail et les casuals pour le loisir. C’est important pour savoir ou cibler les différents segments de clientèle. Nous reviendrons la dessus dans la partie “recommandations”.
LES TEMPS DE TRAJET
Les membres utilisent le service pour effectuer des trajets en général plus courts que les casuals. Il y a une grande majorité de casuals sur les trajets de plus d’une heure.
Les trajets de moins d'une seconde sont surement des erreurs système.
Les trajets de moins d’une minute sont surement dus à un vélo défectueux, l’utilisateur s’en rend compte et rend le vélo directement (ces informations peuvent s'avérer utile dans un cadre d’analyse qualité).
Les trajets de moins de 4min peuvent être de très courts trajets, ou alors l’utilisateur a pris un vélo “classique” dans une station ou aucun vélo électrique n'était disponible et s’est déplacé jusqu'à une autre station pour récupérer un vélo électrique, malheureusement nous sommes limités par la confidentialite des donnees pour mener cette analyse supplémentaire (pas de customer_id et impossibilité d’utiliser les données de carte de crédit).
Les trajets de moins de 15min et de moins d’une heure sont des trajets courts réguliers, pour se rendre au travail par exemple ou se rendre d’un point A à un point B.
Les trajets de plus d' une heure peuvent être perçus comme des randonnées cyclistes pour le plaisir ou une sortie sur le bord du lac en vélo. Encore une fois, notre hypothèse sur l’utilisation du service par les membres dans le cadre du travail est confirmée.
Recommandations
Afin d’augmenter le pourcentage de membres parmi les utilisateurs de Cyclistic, plusieurs actions concrètes basées sur les données peuvent être envisagées.
DOUBLE TARIFICATION DES ABONNEMENTS.
Premièrement afin de capturer le plus fort achalandage dans la période d’Avril à Septembre, il semble indispensable de proposer un abonnement mensuel.
Mais attention, cette double tarification doit toujours inciter à prendre l’abonnement annuel. Il y a un risque que certains membres qui avaient l’abonnement annuel et n’utilisaient les vélos que d’Avril à Septembre arrêtent de payer l’abonnement annuel pour prendre des abonnements mensuels seulement d’Avril à Septembre. Il faut donc être très vigilant sur la tarification pour pas que cette stratégie se retourne contre Cyclistic.
PARTENARIAT AVEC DES EMPLOYEURS
Pour inciter les casuals à utiliser le service pour aller au travail, des partenariats avec des entreprises locales pourraient être envisagés afin d’inclure l’abonnement dans la rémunération de l'employé ou proposer des réductions aux employés de certaines entreprises. Des campagnes de prévention et de sensibilisation sur les bienfaits d’une pratique cycliste régulière pourraient être diffusées par le biais des employeurs.
PARTENARIATS AVEC DES FESTIVALS OU DES ÉVÉNEMENTS SPORTIFS.
Si les casuals préfèrent utiliser les vélos pour le loisir, des partenariats avec des événements sportifs ou des festivals par exemple pourraient être une bonne idée. Proposer par exemple des avantages dans les festivals pour les membres comme par exemple un accès à un salon privé Cyclistic ou une consommation gratuite. Les partenariats avec des événements sportifs peuvent aussi être une bonne opportunité de convertir des casuals en membres. Les randonnées de vélo, triathlons ou diverses courses de vélos pourraient représenter un atout de choix. Les événements sportifs pourraient alors offrir des avantages aux membres ou alors leur offrir la participation en échange de l’utilisation des vélos de Cyclistic dans le cadre de l'événement. Cyclistic pourrait aussi organiser son propre événement sportif en utilisant ses vélos et offrir la participation aux membres ou leur offrir une participation a prix réduit.
OFFRIR DES RÉDUCTIONS ÉTUDIANTES SUR LES ABONNEMENTS (ANNUELS SEULEMENT).
La double tarification à destination des étudiants semble être une bonne manière de tendre la main à un segment de clientèle avec des moyens généralement plus modestes. C’est un bon moyen de fidéliser la clientèle a un moment où ils en ont vraiment besoin. Les étudiants pourront ainsi développer de bonnes habitudes de cyclistes pour plus tard au travail.
STREET MARKETING ET PRÉSENCE DE RUE
Les lieux proches du lac, le port ou Lincoln park semblent représenter des cibles de choix pour des opérations marketing sur le terrain. Comme la concentration des casuals se fait en ces lieux et surtout pendant les beaux jours d'été, une présence dans ces zones d’achalandage dans le cadre de campagnes de sensibilisation santé ou de marketing peuvent représenter une opportunité significative de transformer des non membres en membres et de prospecter pour de nouveaux clients.
CRÉATION D’UNE APPLICATION
La création d’une application web et mobile pourrait faciliter et rendre plus attractive l’utilisation du service. Il pourrait être envisagé d’obliger les casual à créer un compte membre même pour un trajet simple et ainsi avoir plus de données à intégrer dans nos futures analyses, et mieux coller aux attentes de chaque segment de clientèle. Une application peut aussi être un bon vecteur pour proposer des enquêtes de satisfaction et de qualité du service. Si la direction exécutive de Cyclistic ne souhaite pas imposer le téléchargement de l’application à ses utilisateurs, il est possible de naturellement les attirer dessus grâce à des offres promotionnelles ou à un interface attractif.
SCOOTER ÉLECTRIQUES
Il serait intéressant de connaître la proportion de scooters électriques dans la flotte de Cyclistic afin de la comparer avec celle de sa concurrence. Les données ont démontré que les casuals utilisaient plus de scooters électriques que les membres. Si la flotte de Cyclistic ne reflète pas cette préférence, cela peut expliquer que certains casuals rechignent à devenir membres (surtout si les entreprises concurrentes en proposent). Il faudrait alors probablement augmenter la flotte de scooters électriques.
RÉDUCTIONS POUR LES MEMBRES SUR LES TRAJETS DE PLUS D’UNE HEURE.
Comme les casuals ont l’habitude de faire des trajets plus longs, il pourrait être intéressant d'offrir des réductions aux membres sur les longs trajets pour inciter les casuals à devenir membres. Un système de bonification des longues distances pourrait aussi très bien être envisagé par le biais de l’application et seulement pour les membres. Un système de compétition inter-membres pourrait être créé avec des défis sur les distances parcourues par exemple. Des défis “jour de pluie” pourrait aussi être envisagés pour booster l’utilisation du service pendant ces journées moins achalandées.